
About 6 months ago, I resigned from my comfortable Engineering Manager position to explore new opportunities. After some rest and vacation time, I wondered what to do next.
I have always been drawn to indie hacking, so I started brainstorming ideas - “Hey, I’ve spent years applying machine learning to catch cyber bad guys… what if I could turn that experience into my own product?”
I wasn’t interested in the traditional startup path of raising VC funding, building a large team, and working endless hours. Instead, I wanted to stay small and build a bootstrapped product I could sell to a focused customer base.
After doing some market research (serious Googling and coffee chats with potential customers), I embarked on a journey with a friend and ex-colleague to build a Sensitive Data Detection SDK - a library that scans text or files to find potentially sensitive data.
In this blog post, I’ll explain the world of sensitive information detection, why it is a problem, what are the current solutions, and how AI is going to revolutionize this field.
The Data Security Problem
Today’s businesses store enormous amounts of data. Some of the data can be considered “classified”: user’s personal identifiers, financial data, legal information, intellectual property, and even medical information.
Even if an organization doesn’t care about protecting all of this data, they have to - this data is also subject to different regulation policies - like GDPR, HIPAA, and more.
Now the organization’s goal is to prevent the leakage of its sensitive data. Putting aside how to monitor data and prevent its leakage, just finding the sensitive data is harder than it sounds.
Why Is Data Security Hard
Sensitive data comes in many forms - from structured data like social security numbers and credit card numbers to unstructured content like medical conditions and legal agreements. This variety requires deep understanding of security risks and complex definitions of sensitive entities.
Adding to the challenge, sensitive information isn’t centralized - it’s scattered across databases, documents, and emails. Each organization also has unique security needs, like Walmart considering customer IDs as sensitive information.
Current Solutions Are Not Enough
The dominant data security products in late 2024 are just falling short of protecting their customers.
The technology is outdated - they use regex patterns to find common sensitive information formats and then run basic validation algorithms to reduce false positives. Even the more advanced solutions that examine context merely search for predefined keywords around detected entities.
This is why customers are ending up with alert fatigue, stop looking at alerts, and miss real breaches.
Case Study
Testing an existing solution on random documents revealed numerous false positives, including this example from a PDF with a False-Positive detection of a credit card:
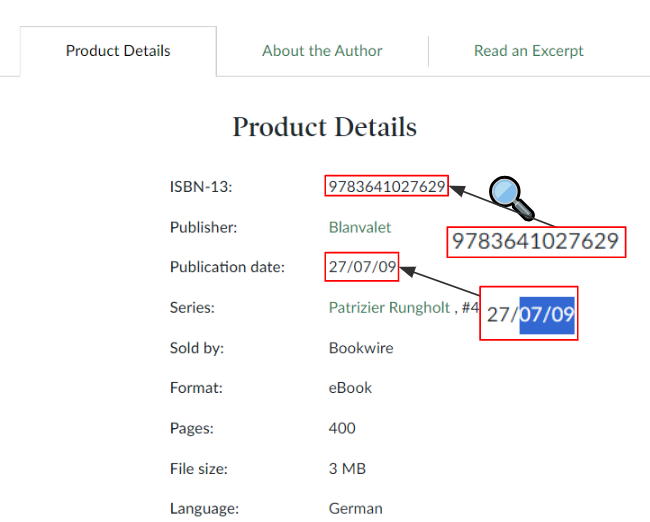
- The number
9783641027629was flagged as a credit card. - It passed Luhn checksum validation.
- The publication date was mistaken for an expiration date.
While the pattern matching worked, the solution failed to understand that this was clearly book metadata, not payment information. Humans can tell the difference because we understand the context.
Data Security Next-Gen
We reached a conclusion that simple pattern-based search results are… well, embarrassing.
Think about it - to tell the difference between a credit card and a book ISBN, we humans naturally understand the context around these numbers. But how do we make a computer understand the semantic meaning of text?
Enter AI models, once again stealing the show.
Classification models
While Large Language Models are making headlines for their text understanding capabilities, they’re not always the best tool for the job. For sensitive data detection, encoder-based models like BERT excel at creating compact semantic representations - perfect for classification tasks.
These models are not just more efficient to run, they’re specifically designed for classification with dedicated output layers that provide clean, consistent predictions. Unlike LLMs that generate free-form text, they output a single class from a predefined set of categories.
Building a sensitive information classifier requires carefully curated training data. Since sensitive information isn’t typically published on kaggle, we need to work harder: scraping available data, faking some, or generating it using an LLM. With this dataset, we can fine-tune a pre-trained BERT model to create a robust classifier specifically optimized for detecting sensitive information.
The Funnel Approach
The next generation of data security requires another step of AI-powered filtering on top of traditional pattern matching and validation.
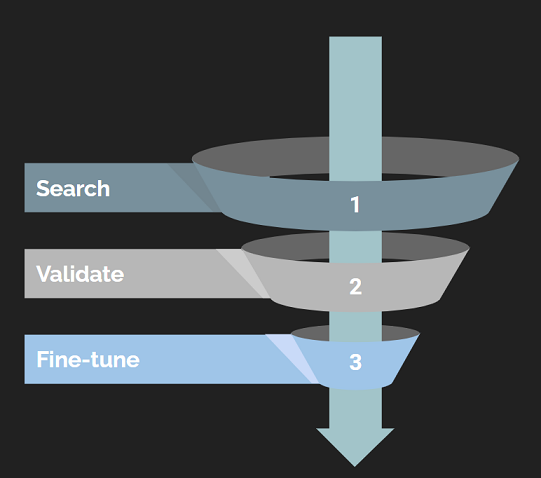
This final layer uses an AI classification model that predicts whether the surrounding text context matches the type of suspected sensitive entity.
Document Classification
Beyond verifying individual entities, we can classify entire documents to better understand the context. Is it a financial transaction, company policy, legal agreement, or CV? This classification adds confidence to our detection.
For example, an International Banking Account Number (IBAN) in a financial document will be flagged as sensitive, but an IBAN inside a charity flyer requesting donations to be wired to this IBAN is actually intended to be public and should not trigger an alert.
Smarter Policies
The way companies customize data security products to their use cases is through policies. The user chooses what sensitive information types they want to enable in a policy, and what severity to assign to alerts to signify importance and mitigation priority.
If each detection result also includes the classification of the document it was found in, users can create policies that take this into consideration, triggering alerts on entities only for certain document types or adjusting alert severity accordingly.
Customer-Specific Models
In my vision, the next phase of embedding AI in data security is fine-tuning the models on the customer’s data. While our base models are trained on diverse data, they can be fine-tuned for each customer’s use case: the customer’s data will be scanned once and labeled. Then, the model will be fined-tuned on this data, and lastly, the trained model will be deployed to the customer.
Furthermore, the model can be fed with data from false detections and relearn their correct classification to avoid alerting again on similar content.
Conclusion
I predict that soon enough, during 2025, solutions will start introducing the AI-enhanced detections, the alerts they raise will get more relevant, and customers will start trusting them again. Vendors that will not do it, will stay behind and slowly disappear.
This rundown should give you an intro to sensitive data detection in the data security world. I hope you enjoyed! :)
Further reading
- To further understand how sensitive information types are commonly defined, you can check out Microsoft’s published Sensitive information types.
- I found Google DLP almost unusable due to the volume of spam it produces - this blog post shows it .
- Some vendors are already talking about advancing sensitive data classification in the AI age.
Comments powered by Disqus.